Unit Testing with AutoFixture to generate TestCase data
When writing unit tests I often find myself having to come up with these kind of random test case data:
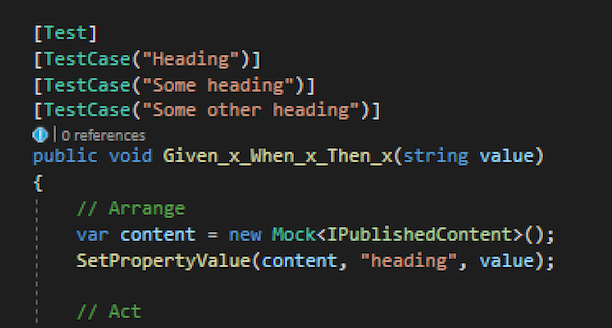
See the reason for having at least two test data cases is because I want to make sure that a value is not hardcoded in my implementation code, which could potentially give me a false positive test if I only had on single test data case. The value itself is not important for the test, it can by whatever, as long as it’s not the same every time.
Having a single test data case could potentially give me a false positive test if my heading was hardcoded in my implementation code.
But I recently discovered a package called AutoFixture which not only replaces all of the test case data in my tests but also saves me the trouble of having to come up with these random values myself. Using AutoFixture my previous example can be rewritten like this:
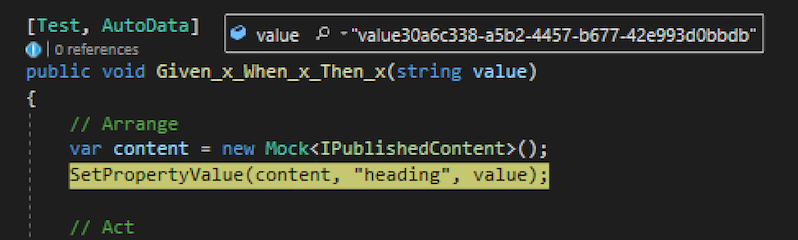
Using the attribute [AutoData] on my previous example the heading string value will be populated with a random string on every test run, as demonstrated here when debugging my test.
This works for more than just string values, AutoFixture can regenerate any kind of system datatype like integers, decimals etc.
AutoFixture can even generate instances of implementation classes and mocks!
Not only that, but AutoFixture can even generate random instances of implementation classes and mocks! This way we can improve this example further by moving the IPublishedContent mocking in to a parameter as well:
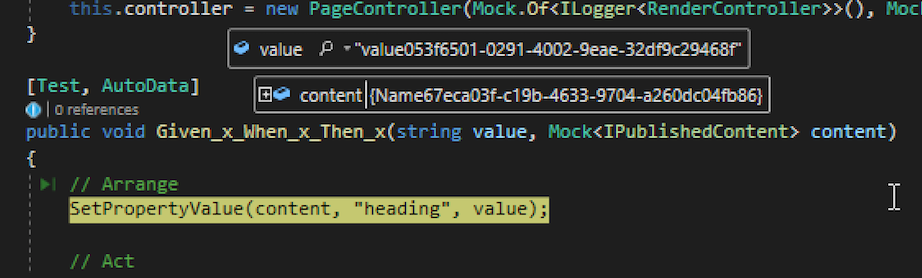
So as you can see, not only does AutoFixture replace all of the test case attributes, but it also reduces the Arrange section inside of your tests making your tests a lot smaller and easier to read.
Not only does AutoFixture replace all of the test case attributes, it also reduces the Arrange section of your tests
These are just some basic examples of how to use AutoFixture, there’s a ton of other useful ways you can utilize AutoFixture in your tests. For example by creating your own custom AutoData attributes to serve your exact needs, which I might cover in a future blogpost.
Special thanks to Marc and Bjarke for pointing me in the direction of AutoFixture during my latest pull request to Umbraco during #hacktoberfest2021. Hope this can be useful to someone!
Cheers! ❤️