Stress-free production deployments
I remember in the early days of my career the stress I would have before each production deploy. I never had a good feeling in the stomach on those days, constantly fearing that something would blow up or even worse: that data would be lost forever!
It’s ironic looking back on this since these weren’t even business critical sites, they were usually really small company sites with almost no traffic at all (the only one who would notice if the site was down was probably the client themselves.)
Today I work with some of the biggest clients in the country and deploying to production is as stress-free as getting a cup of coffee. While writing this blog post it’s Tuesday and I’ve already done three deploys this week to three different production sites and another one is currently running as we speak.
So does this calm feeling when deploying come from experience? No, it come from proper deployment strategies! See back in the days we would do cowboy deploys straight to production using tools like Visual Studio Publish or even worse: FTP uploads straight to the production server. 😱 This was horrible! No wonder this caused us stress and sleepless nights.
I don’t know if it’s a sign of getting older but I find myself today being more interested in talking about devops related configuring and deploy strategies than actual coding (I also love memes, which you probably noticed by now) so I thought I would cover the develop and deploy strategy we use at work and hopefully it might help someone improve their own strategy. Or at least send a link of this blog post to your team lead and they can apply it. 😉
Feature branches:
Every developer works in feature branches which are branched from the develop branch. We usually name these feature branches after the ticket number in JIRA, that way we can link a ticket to a specific branch. So a feature branch usually looks like this: feature/GOVR-1245-featured-articles.
GOVR is the short-name for the client, 1245 is the ticket number in JIRA and featured-articles is a short description of the feature which gives a better overview when listing local branches.
Code review:
When a developer is satisfied with a feature, a pull request is sent to every co-worker in that skill. So backend developers sends PR:s to other backend developers etc.
In order for a PR to be merged, at least one co-worker must review and approve this feature branch. This is to ensure high code quality and that no obvious mistakes have been made. (The number of times my co-workers have saved my ass at this stage is ridiculously high.)
Continous test runs:
When a PR is approved and merged our build server Teamcity will create a continous deployment (covered in the next step), but before this step Teamcity will run every single Unit and Integration test in our solution and if any test fails the deployment will be stopped and a notification is sent to the developers.

This step makes sure that a developer haven’t missed running all the tests locally before creating the PR, or if a merge have resulted in failing tests. If this happens be prepared for a slack meme!

Continous deployment:
When all the tests are green, Teamcity will create a package to Octopus Deploy which will deploy these changes to our CI (Continous Integration) server. This server is just used as a verification step before it reaches the QA server. Anyone in the organization can browse the CI server and see that it is up and running before deploying all the latest changes to the QA server.
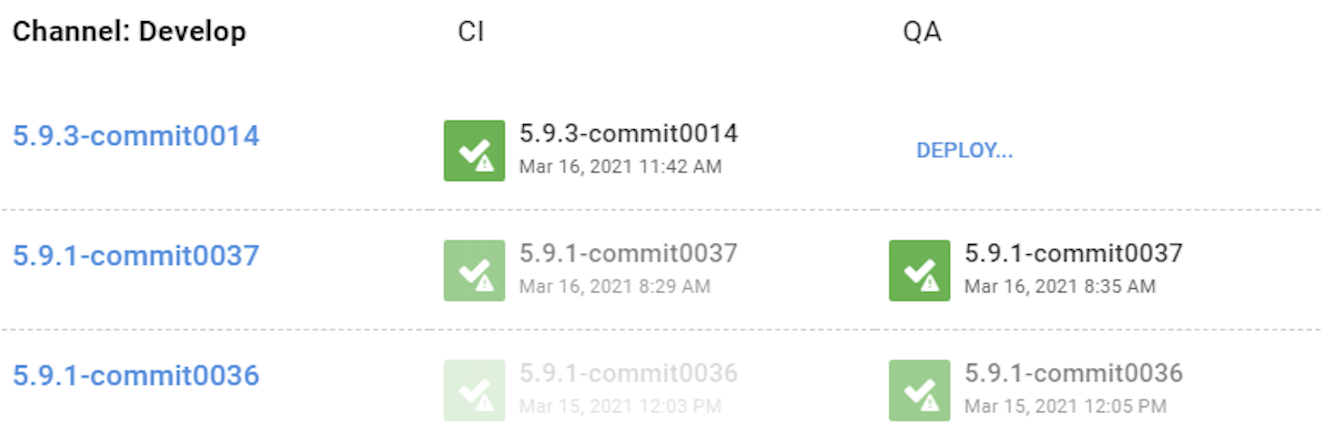
The reason for having the CI step and not deploying straight to the QA server is because it would be very frustrating for our QA managers who are reviewing features on the QA server. By having the CI step, we can schedule a few deployments to QA on a specific time of day that the QA managers are aware of.
QA (Quality Assurance) Server:
Once the feature have reached the QA Server our QA managers will try to break our feature in any way they can possibly think of. It never ceases to amaze me the creativity of QA managers have when trying to break our features.

QA should find nothing!
Your motto should be “QA should find nothing!”. Don’t use QA as a safety net, instead consider every time a QA finds a bug on your feature as a failure on your part and make sure you don’t make that mistake again. Read more about this concept here.
Release branches:
Once QA is happy and our weekly sprint is completed we create a release branch. These release branches follows the major-minor-patch format so a release might look like this: release/1.5.7.
We also tag these release branches for several reasons. One reason is that it’s easy to see in the commit history when release was made, and also Teamcity will update the Assembly version of our release build. See my other blogpost on this topic.
Staging Server:
Once a release branch has been created it gets deployed to our Staging server. We have set up our channels in Octopus Deploy so it is impossible to deploy to Staging (or production) without first creating a release branch. And if an update needs to be made, a patch release will have to be created.

UAT (User Acceptance Testing):
At this stage the client is informed that a new release have been deployed to the staging environment together with a list of all the feature they need to test. If we have done our job right they will find nothing, but there might be misunderstandings or lack of communications that might lead to us having to adjust things and that is done using the already mentioned patch release.
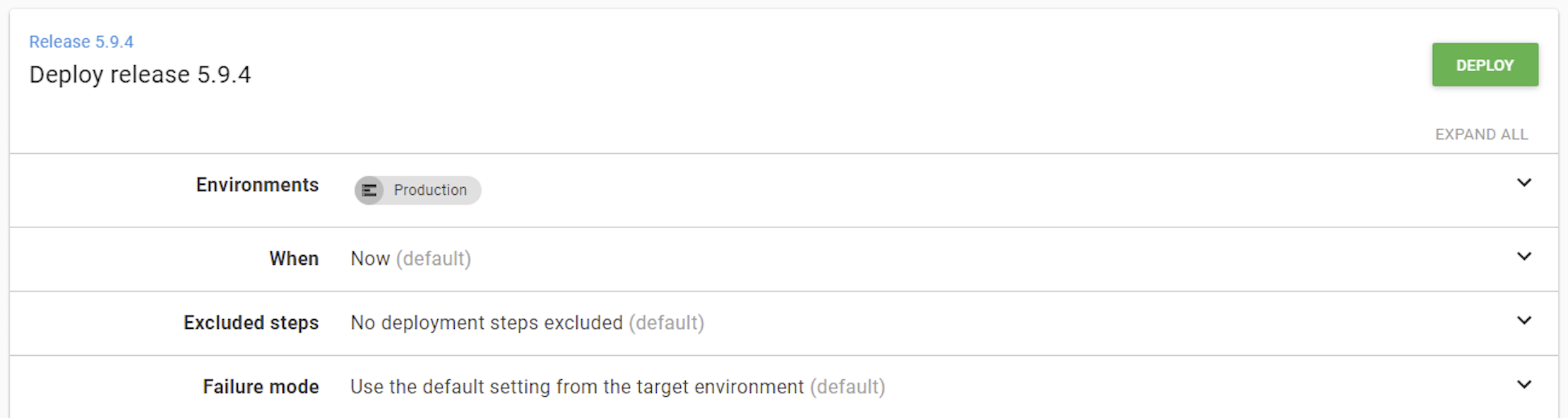
Deploy to production:
When the release branch have been approved by the client, deploying to production is as easy as a click of a big green button in Octopus Deploy (you don’t need to be a developer to perform a deploy, you might be a QA / Project manager).
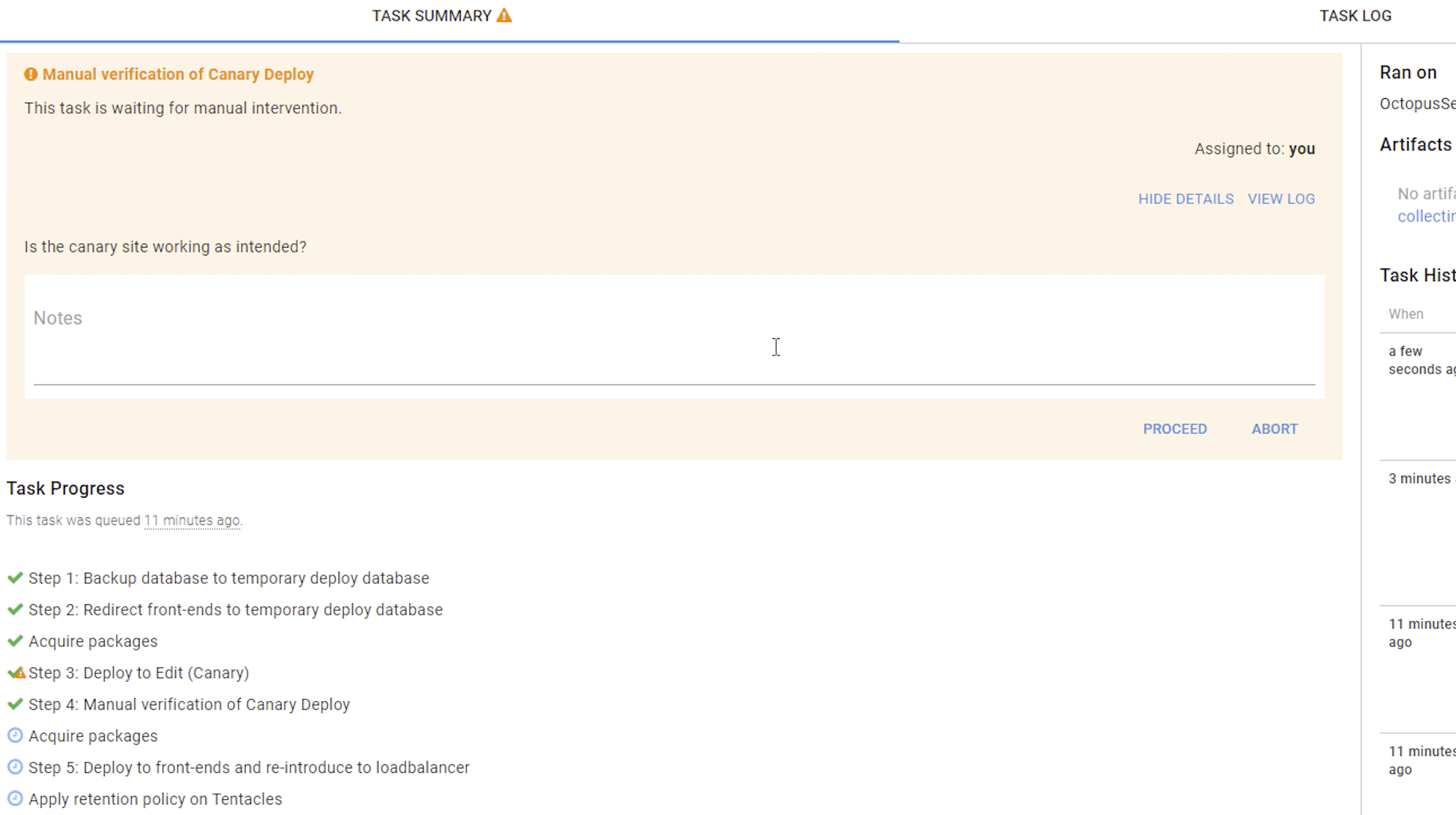
Canary Deploy:
We use a strategy called “Canary Deploy” which means that the first thing that happens is that one of our production servers are taken out of the load balancer and the new release is then deployed only to that server.
Then there is a manual verification step which means you need to browse that canary server and check to see that the new release is working as expected before proceeding with the deploy. If you find something wrong on the canary this step is revertible, meaning the server will go back its previous state before the deploy.
Zero downtime:
When proceeding with the deploy a rolling update strategy is performed, meaning that every server is taken out of the load balancer one by one before the deploy package is applied. If the deploy is successful it gets re-introduced to the load balancer.
This way we have zero downtime during the deployment and any server no yet deployed is placed in a readonly state and a maintenance banner is shown to visitors until the deploy has finalised.
Rollback:
Obviously if any deploy step fails (or succeeds but you find a faulty behaviour) the deploy is revertible so you can rollback the entire deploy and all servers to their previous state before the deploy.
No Friday deployments:
This is probably more a religious rule more than anything, since our deployments are so stress-free and controlled it wouldn’t be a problem deploying to production on a Friday, but we usually make a rule not to.
No one wants to work on the weekend and there’s nothing that can’t wait until Monday. Weekends should be spent with your loved once and not in front of a computer.

Hope this was helpful or at least amusing to some.
Cheers friends! ❤️